| Syntax Element | Description |
|---|---|
%a | Specifies the activation ID of the database. |
%c | Specifies the copy number of the backup piece within a set of duplexed backup pieces. If you did not duplex a backup, then this variable is 1 for backup sets and 0 for proxy copies. If one of these commands is enabled, then the variable shows the copy number. The maximum value for %c is 256. |
%d | Specifies the name of the database. |
%D | Specifies the current day of the month from the Gregorian calendar in format DD. |
%e | Specifies the archived log sequence number. |
%f | Specifies the absolute file number. |
%F | Combines the DBID, day, month, year, and sequence into a unique and repeatable generated name. This variable translates into c-IIIIIIIIII-YYYYMMDD-QQ, where:
|
%h | Specifies the archived redo log thread number. |
%I | Specifies the DBID. |
%M | Specifies the month in the Gregorian calendar in format MM. |
%N | Specifies the tablespace name. |
%n | Specifies the name of the database, padded on the right with x characters to a total length of eight characters. For example, if the prod1 is the database name, then the padded name is prod1xxx. |
%p | Specifies the piece number within the backup set. This value starts at 1 for each backup set and is incremented by 1 as each backup piece is created. Note: If you specify PROXY, then the %p variable must be included in the FORMAT string either explicitly or implicitly within %U. |
%s | Specifies the backup set number. This number is a counter in the control file that is incremented for each backup set. The counter value starts at 1 and is unique for the lifetime of the control file. If you restore a backup control file, then duplicate values can result. Also, CREATE CONTROLFILE initializes the counter back to 1. |
%t | Specifies the backup set time stamp, which is a 4-byte value derived as the number of seconds elapsed since a fixed reference time. The combination of %s and %t can be used to form a unique name for the backup set. |
%T | Specifies the year, month, and day in the Gregorian calendar in this format: YYYYMMDD. |
%u | Specifies an 8-character name constituted by compressed representations of the backup set or image copy number and the time the backup set or image copy was created. |
%U | Specifies a system-generated unique filename (default). The meaning of %U is different for image copies and backup pieces. For a backup piece, %U specifies a convenient shorthand for %u_%p_%c that guarantees uniqueness in generated backup filenames. If you do not specify a format when making a backup, then RMAN uses %U by default.For an image copy of a datafile, %U means the following:data-D-%d_id-%I_TS-%N_FNO-%f_%uFor an image copy of an archived redo velog, %U means the following: arch-D_%d-id-%I_S-%e_T-%h_A-%a_%uFor an image copy of a control file, %U means the following: cf-D_%d-id-%I_%u |
%Y | Specifies the year in this format: YYYY. |
%% | Specifies the literal '%' character. For example, %%Y translates to the string %Y. |
Monday, 16 April 2012
Rman format specifications
Comparing of RMAN Backup Compression Levels
There are different compression levels with Oracle 11g R2. BASIC, LOW, MEDIUM and HIGH are the four different compression levels. We must have “Advanced Compression” option license to use LOW, MEDIUM and HIGH levels of compression. In this article, I will do the tests at 4 compression levels. We will compare compression levels for backup duration and backup size.
So let’s just our test.
I wrote a shell script like the following. Thus, you can watch your spare time.
# top load average: 1.12, 0.82, 0.75
Backup Size: 636M
2- LOW compression level test.
# top load average: 1.34, 0.85, 0.74
Backup Size: 797M
3- MEDIUM compression level test.
# top load average: 1.38, 0.93, 0.77
Backup Size: 674M
4- HIGH compression level test.
# top load average: 1.20, 1.07, 0.88
Backup Size: 485M
5- Normal backup test. Change content of our rman_compression_test.sh script with following lines
# top load average: 2.42, 1.56, 1.17
Backup Size: 4.0G
So let’s just our test.
I wrote a shell script like the following. Thus, you can watch your spare time.
# vi rman_compression_test.shAdd following lines to rman_compression_test.sh script and save it.
echo “RMAN Backup Start Date :” `date ‘+%d.%m.%Y %H:%M:%S’`Let us set the location of our backup files.
StartTime=$(date +%s)
export NLS_LANG=AMERICAN export NLS_DATE_FORMAT=’DD-MON-YYYY HH24:MI:SS’
rman target / << EOSQL
backup as compressed backupset database;
EOSQL
EndTime=$(date +%s)
DiffTime=$(( $EndTime – $StartTime ))
echo “RMAN Backup Finished.”
echo “Backup End Date :” `date ‘+%d.%m.%Y %H:%M:%S’`
echo “RMAN Backup Duration :” $DiffTime
# rman target /1- BASIC compression level test. let’s see our recent compression level.
RMAN> CONFIGURE CHANNEL DEVICE TYPE DISK FORMAT ‘/oracle/yedek/bck_test11g/%U’;
# rman target /We are using BASIC level. Now let’s back up of our 10GB database as compressed.
RMAN> SHOW COMPRESSION ALGORITHM ;
RMAN configuration parameters for database with db_unique_name DBARGE are:
CONFIGURE COMPRESSION ALGORITHM ‘BASIC’ AS OF RELEASE ‘DEFAULT’ OPTIMIZE FOR LOAD TRUE;
# . rman_compression_test.shThe load average was during the backup:
RMAN Backup Start Date : 13.03.2012 16:19:33
…..
Recovery Manager complete.
RMAN Backup Finished.
Backup End Date : 13.03.2012 16:26:32
RMAN Backup Duration : 419
# top load average: 1.12, 0.82, 0.75
Backup Size: 636M
2- LOW compression level test.
# rman target /Now we are using the LOW level. let’s start backup.
RMAN> CONFIGURE COMPRESSION ALGORITHM ‘LOW’;
old RMAN configuration parameters:
CONFIGURE COMPRESSION ALGORITHM ‘BASIC’ AS OF RELEASE ‘DEFAULT’ OPTIMIZE FOR LOAD TRUE;
new RMAN configuration parameters:
CONFIGURE COMPRESSION ALGORITHM ‘LOW’ AS OF RELEASE ‘DEFAULT’ OPTIMIZE FOR LOAD TRUE;
new RMAN configuration parameters are successfully stored
# . rman_compression_test.shThe load average was during the backup:
RMAN Backup Start Date : 13.03.2012 16:30:36
…..
Recovery Manager complete.
RMAN Backup Finished.
Backup End Date : 13.03.2012 16:33:45 RMAN
Backup Duration : 189
# top load average: 1.34, 0.85, 0.74
Backup Size: 797M
3- MEDIUM compression level test.
# rman target /Now we are using the MEDIUM level. let’s start backup.
RMAN> CONFIGURE COMPRESSION ALGORITHM ‘MEDIUM’;
old RMAN configuration parameters:
CONFIGURE COMPRESSION ALGORITHM ‘LOW’ AS OF RELEASE ‘DEFAULT’ OPTIMIZE FOR LOAD TRUE;
new RMAN configuration parameters:
CONFIGURE COMPRESSION ALGORITHM ‘MEDIUM’ AS OF RELEASE ‘DEFAULT’ OPTIMIZE FOR LOAD TRUE;
new RMAN configuration parameters are successfully stored
# . rman_compression_test.shThe load average was during the backup:
RMAN Backup Start Date : 13.03.2012 16:36:21
…..
Recovery Manager complete.
RMAN Backup Finished.
Backup End Date : 13.03.2012 16:40:19
RMAN Backup Duration : 238
# top load average: 1.38, 0.93, 0.77
Backup Size: 674M
4- HIGH compression level test.
# rman target /Now we are using the HIGH level. let’s start backup.
RMAN> CONFIGURE COMPRESSION ALGORITHM ‘HIGH’;
old RMAN configuration parameters:
CONFIGURE COMPRESSION ALGORITHM ‘MEDIUM’ AS OF RELEASE ‘DEFAULT’ OPTIMIZE FOR LOAD TRUE;
new RMAN configuration parameters:
CONFIGURE COMPRESSION ALGORITHM ‘HIGH’ AS OF RELEASE ‘DEFAULT’ OPTIMIZE FOR LOAD TRUE;
new RMAN configuration parameters are successfully stored
# . rman_compression_test.shThe load average was during the backup:
RMAN Backup Start Date : 13.03.2012 16:42:21
…..
Recovery Manager complete.
RMAN Backup Finished.
Backup End Date : 13.03.2012 17:34:30
RMAN Backup Duration : 3129
# top load average: 1.20, 1.07, 0.88
Backup Size: 485M
5- Normal backup test. Change content of our rman_compression_test.sh script with following lines
# vi rman_compression_test.shExecute script.
echo “RMAN Backup Start Date :” `date ‘+%d.%m.%Y %H:%M:%S’`
StartTime=$(date +%s)
export NLS_LANG=AMERICAN export NLS_DATE_FORMAT=’DD-MON-YYYY HH24:MI:SS’
rman target / << EOSQL
backup as backupset database;
EOSQL
EndTime=$(date +%s)
DiffTime=$(( $EndTime – $StartTime ))
echo “RMAN Backup Finished.”
echo “Backup End Date :” `date ‘+%d.%m.%Y %H:%M:%S’`
echo “RMAN Backup Duration :” $DiffTime
#. rman_compression_test.shThe load average was during the backup:
RMAN Backup Start Date : 13.03.2012 17:37:51
…..
Recovery Manager complete.
RMAN Backup Finished.
Backup End Date : 13.03.2012 17:42:30
RMAN Backup Duration : 279
# top load average: 2.42, 1.56, 1.17
Backup Size: 4.0G
| Compression Level | Backup Size | Backup Duration |
| NORMAL | 4.0G | 279 sec |
| BASIC | 636M | 419 sec |
| LOW | 797M | 189 sec |
| MEDIUM | 674M | 238 sec |
| HIGH | 485M | 3129 sec |
Thursday, 12 April 2012
Suspending and Resuming a Database
The ALTER SYSTEM SUSPEND statement suspends a database by halting all input and output (I/O) to datafiles (file header and file data) and control files, thus allowing a database to be backed up without I/O interference. When the database is suspended all preexisting I/O operations are allowed to complete and any new database accesses are placed in a queued state.
The suspend command suspends the database, and is not specific to an instance. Therefore, in an Oracle Real Application Clusters environment, if the suspend command is entered on one system, then internal locking mechanisms will propagate the halt request across instances, thereby quiescing all active instances in a given cluster. However, do not start a new instance while you suspend another instance, since the new instance will not be suspended.
Use the ALTER SYSTEM RESUME statement to resume normal database operations. You can specify the SUSPEND and RESUME from different instances. For example, if instances 1, 2, and 3 are running, and you issue an ALTER SYSTEM SUSPEND statement from instance 1, then you can issue a RESUME from instance 1, 2, or 3 with the same effect.
The suspend/resume feature is useful in systems that allow you to mirror a disk or file and then split the mirror, providing an alternative backup and restore solution. If you use a system that is unable to split a mirrored disk from an existing database while writes are occurring, then you can use the suspend/resume feature to facilitate the split.
The suspend/resume feature is not a suitable substitute for normal shutdown operations, however, since copies of a suspended database can contain uncommitted updates.
Do not use the ALTER SYSTEM SUSPEND statement as a substitute for placing a tablespace in hot backup mode. Precede any database suspend operation by an ALTER TABLESPACE BEGIN BACKUP statement.
The following statements illustrate ALTER SYSTEM SUSPEND/RESUME usage. The V$INSTANCE view is queried to confirm database status.
SQL> ALTER SYSTEM SUSPEND;
System altered
SQL> SELECT DATABASE_STATUS FROM V$INSTANCE;
DATABASE_STATUS
———
SUSPENDED
SQL> ALTER SYSTEM RESUME;
System altered
SQL> SELECT DATABASE_STATUS FROM V$INSTANCE;
DATABASE_STATUS
———
ACTIVE
The suspend command suspends the database, and is not specific to an instance. Therefore, in an Oracle Real Application Clusters environment, if the suspend command is entered on one system, then internal locking mechanisms will propagate the halt request across instances, thereby quiescing all active instances in a given cluster. However, do not start a new instance while you suspend another instance, since the new instance will not be suspended.
Use the ALTER SYSTEM RESUME statement to resume normal database operations. You can specify the SUSPEND and RESUME from different instances. For example, if instances 1, 2, and 3 are running, and you issue an ALTER SYSTEM SUSPEND statement from instance 1, then you can issue a RESUME from instance 1, 2, or 3 with the same effect.
The suspend/resume feature is useful in systems that allow you to mirror a disk or file and then split the mirror, providing an alternative backup and restore solution. If you use a system that is unable to split a mirrored disk from an existing database while writes are occurring, then you can use the suspend/resume feature to facilitate the split.
The suspend/resume feature is not a suitable substitute for normal shutdown operations, however, since copies of a suspended database can contain uncommitted updates.
Do not use the ALTER SYSTEM SUSPEND statement as a substitute for placing a tablespace in hot backup mode. Precede any database suspend operation by an ALTER TABLESPACE BEGIN BACKUP statement.
The following statements illustrate ALTER SYSTEM SUSPEND/RESUME usage. The V$INSTANCE view is queried to confirm database status.
SQL> ALTER SYSTEM SUSPEND;
System altered
SQL> SELECT DATABASE_STATUS FROM V$INSTANCE;
DATABASE_STATUS
———
SUSPENDED
SQL> ALTER SYSTEM RESUME;
System altered
SQL> SELECT DATABASE_STATUS FROM V$INSTANCE;
DATABASE_STATUS
———
ACTIVE
Quiescing a Database
Quiesce is used to describe pausing or altering the state of running processes on a computer, particularly those that might modify information stored on disk during a backup, in order to guarantee a consistent and usable backup.
There are times when a DBA needs to perform work on the database that requires no other ACTIVE sessions. This is very common in development databases, where a DBA tries to run a package or a modify a table when the application is till running.
There are also frequent occurrences where too much IT support folks time is spent in bringing lot of application servers down to perform a deployment or some database maintenance. That is where Quiescing comes in.
To put a database(run on one instance and it affects all the instances of the RAC database).
ALTER SYSTEM QUIESCE RESTRICTED;
Quiescing puts the database in mode that does not allow any further connections to become ACTIVE state. It would however wait for all ACTIVE connections to become INACTIVE or terminate. Gladly Oracle provides a query to find sessions which are stopping it from enter into QUIESCE mode.
select bq.sid, ss.user, ss.osuser, ss.type, ss.program
from v$blocking_quiesce bq, v$session ss
where bq.sid = ss.sid;
Once in QUIESCE mode, DBA connections are the only ones that are allowed to be in ACTIVE state. The DBA can then easily lock any object to perform his tasks.
Once done to release the QUIESCE
ALTER SYSTEM UNQUIESCE;
You can query V$INSTANCE view to see active state .
There are times when a DBA needs to perform work on the database that requires no other ACTIVE sessions. This is very common in development databases, where a DBA tries to run a package or a modify a table when the application is till running.
There are also frequent occurrences where too much IT support folks time is spent in bringing lot of application servers down to perform a deployment or some database maintenance. That is where Quiescing comes in.
To put a database(run on one instance and it affects all the instances of the RAC database).
ALTER SYSTEM QUIESCE RESTRICTED;
Quiescing puts the database in mode that does not allow any further connections to become ACTIVE state. It would however wait for all ACTIVE connections to become INACTIVE or terminate. Gladly Oracle provides a query to find sessions which are stopping it from enter into QUIESCE mode.
select bq.sid, ss.user, ss.osuser, ss.type, ss.program
from v$blocking_quiesce bq, v$session ss
where bq.sid = ss.sid;
Note:
In this discussion of quiesce database, a DBA is defined as user SYS or SYSTEM. Other users, including those with the DBA role, are not allowed to issue the ALTER SYSTEM QUIESCE DATABASE statement or proceed after the database is quiesced.Once in QUIESCE mode, DBA connections are the only ones that are allowed to be in ACTIVE state. The DBA can then easily lock any object to perform his tasks.
Once done to release the QUIESCE
ALTER SYSTEM UNQUIESCE;
You can query V$INSTANCE view to see active state .
SQL> select active_state from v$instance;You can see 3 situation. NORMAL – Database is normal state (unquiescing). QUIESCING – Being quiesced, but some non-DBA sessions are still active. There are active sessions QUIESCED – Quiesced. There is no non-DBA sessions are active.
Locally managed tablespace
A tablespace that manages its own extents maintains a bitmap in each datafile to keep track of the free or used status of blocks in that datafile. Each bit in the bitmap corresponds to a block or a group of blocks. When an extent is allocated or freed for reuse, Oracle changes the bitmap values to show the new status of the blocks. These changes do not generate rollback information because they do not update tables in the data dictionary.
Local management of extents automatically tracks adjacent free space, eliminating the need to coalesce free extents. The sizes of extents that are managed locally can be determined automatically by the system. Alternatively, all extents can have the same size in a locally-managed tablespace.
A tablespace that manages its extents locally can have either uniform extent sizes or variable extent sizes that are determined automatically by the system. When you create the tablespace, the UNIFORM or AUTOALLOCATE (system-managed) option specifies the type of allocation.
For system-managed extents, you can specify the size of the initial extent and Oracle determines the optimal size of additional extents, with a minimum extent size of 64 KB. This is the default for permanent tablespaces.
For uniform extents, you can specify an extent size or use the default size, which is 1 MB. Temporary tablespaces that manage their extents locally can only use this type of allocation.
The storage parameters NEXT, PCTINCREASE, MINEXTENTS, MAXEXTENTS, and DEFAULT
STORAGE are not valid for extents that are managed locally. Actually, you cannot create a locally managed SYSTEM tablespace. Locally managed temporary tablespaces must of type “temporary” (not “permanent”).
Advantages
Local management of extents avoids recursive space management operations, which can occur in dictionary-managed tablespaces if consuming or releasing space in an extent results in another operation that consumes or releases space in a rollback segment or data dictionary table. Local management of extents automatically tracks adjacent free space, eliminating the need to coalesce free extents.
Example:
An insert causes a request for an extent
Oracle allocates space in the data tablespace
This causes an update of system tables in the data
dictionary if tablespace is dictionary-managed
Consequently, an update is made to the redo log.
So a large number of inserts in to a tablespace with a small extent size may cause many I/O’s to the system tablespace and consequently the redo log files. Also, large sorts from “read-only” databases may cause many I/O’s to the log file due to system tablespace update for temporary tablespace extent allocation.
How to calculate the size of locally managed tablespaces ?
When creating tablespaces with a uniform extent size it is important to understand that 64 Kbytes per datafile is allocated for the storage management information. When creating database files, add an additional 64 Kbytes to the size of your datafile.
Consider the following example to illustrate the matter:
SQL> CREATE TABLESPACE demo1
DATAFILE ‘D:\Oradata\SAP1\tab\SAP1_demo1.dbf’ SIZE 10M
EXTENT MANAGEMENT LOCAL UNIFORM SIZE 5M;
Tablespace created.
SQL> select bytes from dba_free_space where
TABLESPACE_NAME = ‘DEMO1′;
BYTES
———-
5242880
What happens here is we ask for 5 Mbyte extents in a 10 Mbyte file. After 64 Kbytes is allocated for the bitmap, we are left with one 5 Mbyte extent and one less then 5 Mbytes extent. We cannot use the less then 5 Mbyte extent so it does not show up — it is wasted. This can also happen when you have larger uniform extents when the remainder of space in the datafile is just 64 Kbytes short of being able to accomodate your uniform extent size.
SQL> drop TABLESPACE demo1;
Tablespace dropped.
If you change the test case to allow for the extra 64 Kbytes:
SQL> CREATE TABLESPACE demo1
DATAFILE ‘D:\Oradata\SAP1\tab\SAP1_demo1.dbf’ SIZE 10304K
EXTENT MANAGEMENT LOCAL UNIFORM SIZE 5M;
Tablespace created.
SQL> select bytes from dba_free_space where
TABLESPACE_NAME = ‘DEMO1′;
BYTES
———-
10485760
You can see that when we add 64 Kbytes to the datafile size the full 2 extents you want are there. Locally managed tablespaces should have datafiles that are 64 Kbytes
LARGER then a multiple of their extent size when using uniform sizing.
Sizing LMT
More and more we are using locally managed tablespaces. They offer a large amount of benefits, so why should we not use this new feature?
Some thoughts are needed when you decided to use Uniform Extent Allocation. With the uniform method, you specify an extent size when you create the tablespace, and all extents for all objects created within that tablespace will be that size.
The uniform method also provides an enforcement mechanism, because you can’t override the uniform extent size of locally managed tablespaces when you create a schema object such as a table or an index.
Calculate the Size of Tablespaces
The goal is to allocate as much disk space as really needed and as really used. With the uniform extent allocation you can calculate or even estimate the number of extents you want to allocate. Gaps or unused disk space within the tablespace should be avoided.
Lets assume that we create a tablespace with the uniform extent size of 1 MByte and 10 extents. Remember that locally managed tablespaces will use another 64 KBytes or the Header Bitmap:
10 * 1 * 1024K + 64K = 10304K
Note that all calculations are made in KBytes and that your chosen extent size is the multiple of your defined block size. The following statement creates this locally managed tablespace with a uniform extent size of 1 MByte:
CREATE TABLESPACE uni_test
DATAFILE ‘C:\Oradata\ASU1\tab\uni_test.dbf’
SIZE 10304K
EXTENT MANAGEMENT LOCAL UNIFORM SIZE 1024K;
Check the Size and Number of Extents
Now every object created within the newly created tablespace gets its uniform extent size of 1 MByte:
CREATE TABLE tab_1 (
num NUMBER
) TABLESPACE uni_test;
CREATE TABLE tab_2 (
num NUMBER,
text VARCHAR2(255)
) TABLESPACE uni_test
STORAGE
(INITIAL 100K
NEXT 100K
MINEXTENTS 1
MAXEXTENTS UNLIMITED
PCTINCREASE 0);
CREATE TABLE tab_3 (
num NUMBER,
text VARCHAR2(255),
create_date DATE
) TABLESPACE uni_test
STORAGE
(MINEXTENTS 2
MAXEXTENTS UNLIMITED
PCTINCREASE 0);
If you are including a STORAGE clause when you create tables or indexes, Oracle will allocate as much extents as you indicate to use. Table TAB_1 will be allocated with one extent, table TAB_2 too because you need at least 100 KBytes. Table TAB_3 will be created with two extents. This could also be done by defining an INITIAL value of 2 MBytes.
The allocated blocks and extents can be verified using the view DBA_SEGMENTS:
SELECT segment_name, segment_type, blocks, extents
FROM dba_segments
WHERE owner = ‘TEST’
ORDER BY EXTENTS
/
SEGMENT_NAME SEGMENT_TYPE BLOCKS EXTENTS
——————– —————— ———- ———-
TAB_1 TABLE 256 1
TAB_2 TABLE 256 1
TAB_3 TABLE 512 2
The free space in the tablespace UNI_TEST can be verified using the view DBA_FREE_SPACE:
SELECT tablespace_name, bytes, blocks
FROM dba_free_space
WHERE tablespace_name = ‘UNI_TEST’
/
TABLESPACE_NAME BYTES BLOCKS
—————————— ———- ———-
UNI_TEST 6291456 1536
That means in the tablespace UNI_TEST are still 1536 blocks available. How many extents are these blocks? This can be calculated by multiplying the number of available blocks by the block size and divided by the extent size:
1536 * 4K / 1024K = 6 extents
That fits with our calculations and verifications: 4 extents are already used and another 6
extents could be used to fill up the whole tablespace.
Check the File Size
If you check the physical file size used for the tablespace UNI_TEST you will be surprised: Instead of the calculated 10304 KBytes (10’551’296 Bytes) you will find the disk file’s size of 10’555’392 Bytes. Oracle allocates another block which can not be used for object allocation. Some of the Oracle tools such as the Tablespace Manger shows the total number of blocks according to the disk file size. In our example this are 2577 blocks, but usable are only 2576 blocks minus 64 KBytes (for header bitmap).
Summary
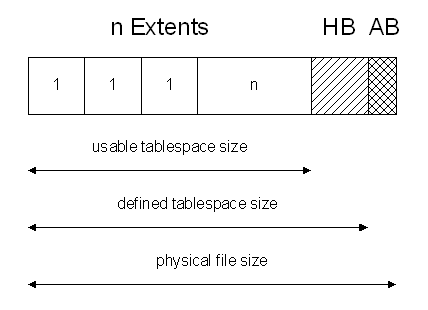
Keep the following rules in mind during the sizing of tablespaces:
Each extent size is the multiple of your defined block size.
The usable tablespace size is the multiple of your estimated number of extents.
The defined tablespace size used during CREATE TABLESPACE statement adds 64
KBytes for the header bitmap (HB) to the usable tablespace size.
The physical file size adds one block (AB) to the defined tablespace size.
Local management of extents automatically tracks adjacent free space, eliminating the need to coalesce free extents. The sizes of extents that are managed locally can be determined automatically by the system. Alternatively, all extents can have the same size in a locally-managed tablespace.
A tablespace that manages its extents locally can have either uniform extent sizes or variable extent sizes that are determined automatically by the system. When you create the tablespace, the UNIFORM or AUTOALLOCATE (system-managed) option specifies the type of allocation.
For system-managed extents, you can specify the size of the initial extent and Oracle determines the optimal size of additional extents, with a minimum extent size of 64 KB. This is the default for permanent tablespaces.
For uniform extents, you can specify an extent size or use the default size, which is 1 MB. Temporary tablespaces that manage their extents locally can only use this type of allocation.
The storage parameters NEXT, PCTINCREASE, MINEXTENTS, MAXEXTENTS, and DEFAULT
STORAGE are not valid for extents that are managed locally. Actually, you cannot create a locally managed SYSTEM tablespace. Locally managed temporary tablespaces must of type “temporary” (not “permanent”).
Advantages
Local management of extents avoids recursive space management operations, which can occur in dictionary-managed tablespaces if consuming or releasing space in an extent results in another operation that consumes or releases space in a rollback segment or data dictionary table. Local management of extents automatically tracks adjacent free space, eliminating the need to coalesce free extents.
Example:
An insert causes a request for an extent
Oracle allocates space in the data tablespace
This causes an update of system tables in the data
dictionary if tablespace is dictionary-managed
Consequently, an update is made to the redo log.
So a large number of inserts in to a tablespace with a small extent size may cause many I/O’s to the system tablespace and consequently the redo log files. Also, large sorts from “read-only” databases may cause many I/O’s to the log file due to system tablespace update for temporary tablespace extent allocation.
How to calculate the size of locally managed tablespaces ?
When creating tablespaces with a uniform extent size it is important to understand that 64 Kbytes per datafile is allocated for the storage management information. When creating database files, add an additional 64 Kbytes to the size of your datafile.
Consider the following example to illustrate the matter:
SQL> CREATE TABLESPACE demo1
DATAFILE ‘D:\Oradata\SAP1\tab\SAP1_demo1.dbf’ SIZE 10M
EXTENT MANAGEMENT LOCAL UNIFORM SIZE 5M;
Tablespace created.
SQL> select bytes from dba_free_space where
TABLESPACE_NAME = ‘DEMO1′;
BYTES
———-
5242880
What happens here is we ask for 5 Mbyte extents in a 10 Mbyte file. After 64 Kbytes is allocated for the bitmap, we are left with one 5 Mbyte extent and one less then 5 Mbytes extent. We cannot use the less then 5 Mbyte extent so it does not show up — it is wasted. This can also happen when you have larger uniform extents when the remainder of space in the datafile is just 64 Kbytes short of being able to accomodate your uniform extent size.
SQL> drop TABLESPACE demo1;
Tablespace dropped.
If you change the test case to allow for the extra 64 Kbytes:
SQL> CREATE TABLESPACE demo1
DATAFILE ‘D:\Oradata\SAP1\tab\SAP1_demo1.dbf’ SIZE 10304K
EXTENT MANAGEMENT LOCAL UNIFORM SIZE 5M;
Tablespace created.
SQL> select bytes from dba_free_space where
TABLESPACE_NAME = ‘DEMO1′;
BYTES
———-
10485760
You can see that when we add 64 Kbytes to the datafile size the full 2 extents you want are there. Locally managed tablespaces should have datafiles that are 64 Kbytes
LARGER then a multiple of their extent size when using uniform sizing.
Sizing LMT
More and more we are using locally managed tablespaces. They offer a large amount of benefits, so why should we not use this new feature?
Some thoughts are needed when you decided to use Uniform Extent Allocation. With the uniform method, you specify an extent size when you create the tablespace, and all extents for all objects created within that tablespace will be that size.
The uniform method also provides an enforcement mechanism, because you can’t override the uniform extent size of locally managed tablespaces when you create a schema object such as a table or an index.
Calculate the Size of Tablespaces
The goal is to allocate as much disk space as really needed and as really used. With the uniform extent allocation you can calculate or even estimate the number of extents you want to allocate. Gaps or unused disk space within the tablespace should be avoided.
Lets assume that we create a tablespace with the uniform extent size of 1 MByte and 10 extents. Remember that locally managed tablespaces will use another 64 KBytes or the Header Bitmap:
10 * 1 * 1024K + 64K = 10304K
Note that all calculations are made in KBytes and that your chosen extent size is the multiple of your defined block size. The following statement creates this locally managed tablespace with a uniform extent size of 1 MByte:
CREATE TABLESPACE uni_test
DATAFILE ‘C:\Oradata\ASU1\tab\uni_test.dbf’
SIZE 10304K
EXTENT MANAGEMENT LOCAL UNIFORM SIZE 1024K;
Check the Size and Number of Extents
Now every object created within the newly created tablespace gets its uniform extent size of 1 MByte:
CREATE TABLE tab_1 (
num NUMBER
) TABLESPACE uni_test;
CREATE TABLE tab_2 (
num NUMBER,
text VARCHAR2(255)
) TABLESPACE uni_test
STORAGE
(INITIAL 100K
NEXT 100K
MINEXTENTS 1
MAXEXTENTS UNLIMITED
PCTINCREASE 0);
CREATE TABLE tab_3 (
num NUMBER,
text VARCHAR2(255),
create_date DATE
) TABLESPACE uni_test
STORAGE
(MINEXTENTS 2
MAXEXTENTS UNLIMITED
PCTINCREASE 0);
If you are including a STORAGE clause when you create tables or indexes, Oracle will allocate as much extents as you indicate to use. Table TAB_1 will be allocated with one extent, table TAB_2 too because you need at least 100 KBytes. Table TAB_3 will be created with two extents. This could also be done by defining an INITIAL value of 2 MBytes.
The allocated blocks and extents can be verified using the view DBA_SEGMENTS:
SELECT segment_name, segment_type, blocks, extents
FROM dba_segments
WHERE owner = ‘TEST’
ORDER BY EXTENTS
/
SEGMENT_NAME SEGMENT_TYPE BLOCKS EXTENTS
——————– —————— ———- ———-
TAB_1 TABLE 256 1
TAB_2 TABLE 256 1
TAB_3 TABLE 512 2
The free space in the tablespace UNI_TEST can be verified using the view DBA_FREE_SPACE:
SELECT tablespace_name, bytes, blocks
FROM dba_free_space
WHERE tablespace_name = ‘UNI_TEST’
/
TABLESPACE_NAME BYTES BLOCKS
—————————— ———- ———-
UNI_TEST 6291456 1536
That means in the tablespace UNI_TEST are still 1536 blocks available. How many extents are these blocks? This can be calculated by multiplying the number of available blocks by the block size and divided by the extent size:
1536 * 4K / 1024K = 6 extents
That fits with our calculations and verifications: 4 extents are already used and another 6
extents could be used to fill up the whole tablespace.
Check the File Size
If you check the physical file size used for the tablespace UNI_TEST you will be surprised: Instead of the calculated 10304 KBytes (10’551’296 Bytes) you will find the disk file’s size of 10’555’392 Bytes. Oracle allocates another block which can not be used for object allocation. Some of the Oracle tools such as the Tablespace Manger shows the total number of blocks according to the disk file size. In our example this are 2577 blocks, but usable are only 2576 blocks minus 64 KBytes (for header bitmap).
Summary
Keep the following rules in mind during the sizing of tablespaces:
Each extent size is the multiple of your defined block size.
The usable tablespace size is the multiple of your estimated number of extents.
The defined tablespace size used during CREATE TABLESPACE statement adds 64
KBytes for the header bitmap (HB) to the usable tablespace size.
The physical file size adds one block (AB) to the defined tablespace size.
Wednesday, 11 April 2012
Block change tracking
when we enable block change tracking, by default an OMF file will be created in DB_CREATE_FILE_DEST location with the initial size of 10M and will grow in 10M of size. This file will record the information of the blocks which are getting changed including their block SCN. We can use already existing file also as change tracker file as follows:
ALTER DATABASE ENABLE BLOCK CHANGE TRACKING USING FILE ‘/u01/oradata/MYSID/rman_change_track.f’ REUSE;
ALTER DATABASE ENABLE BLOCK CHANGE TRACKING USING FILE ‘/u01/oradata/MYSID/rman_change_track.f’ REUSE;
Tuesday, 10 April 2012
SNIPED sessions and ORA-00020: maximum number of processes (%s) exceeded
When you implement the resource limit, the sessions that exceed the IDLE limit is marked as SNIPED in V$SESSION view and you may get “ORA-00020: maximum number of processes (%s) exceeded” error because Oracle doesn’t kill that session in OS level and it assumes it as a “process”. So for this, you need to kill those sessions manually
Here I show a little demonstration of the whole process: – First of all, set the RESOURCE_LIMIT parameter to TRUE to enforce the resource limit in database profiles
- Then create a profile and set IDLE_TIME to 1 minute:
- Create a user and assign the profile to that user:
- Change the PROCESSES parameter to make the maximum number of operating system processes lower
Now open two different terminals and connect to the database with USR user:
Check the view V$PROCESS. It should be 24
Now open third terminal and try to connect to the database with the user USR.You will get an error because the count of the processes will reach the limit:
Now wait for a minute to reach the limit of the IDLE_LIMIT resource (we’ve set it to 1 minute) and query the SYSDATE from any USR session:
That’s the issue. If you try to connect to the database, you’ll get ORA-00020 error again. Please note that SNIPED doesn’t mean that it’s KILLED. It is not either killed, nor active. The user is not able to run any query, however it holds a process on OS level:
Run any query with already connected (and SNIPED) USR user. You’ll get the following error:
Now query V$SESSION and V$PROCESS views again:
The process will be free only when you “exit” from Sql*Plus. Exit from the session that you got an error and query V$PROCESS again:
To kill the SNIPED sessions you have two options. The first option is to run ALTER SYSTEM KILL SESSION command. For this you need to get SID and SERIAL# of the sniped session.
After some seconds you’ll see that the session is cleared from both views:
However, due to some bugs, sometimes you may not get the sessions killed using ALTER SYSTEM KILL SESSSION command. For this, you need to kill the process from OS level.
Run any sql command on the killed session:
(For more information on killing sniped sessions, refer to MOS 96170.1)
Here I show a little demonstration of the whole process: – First of all, set the RESOURCE_LIMIT parameter to TRUE to enforce the resource limit in database profiles
1 2 3 4 5 6 7 | SQL> show parameter resource_limitNAME TYPE VALUE------------------------------------ ----------- ------------------------------resource_limit boolean FALSESQL> alter system set resource_limit=true;System altered. |
1 2 3 | SQL> create profile test_profile limit 2 idle_time 1;Profile created. |
1 2 3 4 5 | SQL> grant dba to usr identified by usr;Grant succeeded.SQL> alter user usr profile test_profile;User altered. |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | SQL> show parameter processNAME TYPE VALUEprocesses integer 150SQL> alter system set processes=25 scope=spfile;System altered.SQL> startup forceSQL> show parameter processesNAME TYPE VALUEprocesses integer 25SQL> select count(1) from v$process; COUNT(1)---------- 22 |
1 | sqlplus usr/usr |
1 2 3 4 5 | SQL> select count(1) from v$process; COUNT(1)---------- 24 |
1 2 3 4 5 6 7 8 | [oracle@localhost ~]$ sqlplus usr/usrERROR:ORA-00020: maximum number of processes (%s) exceededEnter user-name:SQL> |
1 2 3 4 5 6 7 8 9 10 11 12 | SQL> select s.status, count(1), s.username from v$process p, v$session swhere paddr(+)=addrgroup by s.status, s.usernameorder by 1;STATUS COUNT(1) USERNAME-------- ---------- ------------------------------ACTIVE 1 SYSACTIVE 16INACTIVE 2 SYSSNIPED 2 USR 3 |
1 2 3 4 5 | SQL> select count(1) from v$process; COUNT(1)---------- 24 |
1 2 3 4 5 6 | SQL> select sysdate from dual;select sysdate from dual*ERROR at line 1:ORA-02396: exceeded maximum idle time, please connect againSQL> |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | SQL> select s.status, count(1), s.username from v$process p, v$session swhere paddr(+)=addrgroup by s.status, s.usernameorder by 1;STATUS COUNT(1) USERNAME-------- ---------- ------------------------------ACTIVE 1 SYSACTIVE 16INACTIVE 2 SYSSNIPED 1 USR 4SQL> select count(1) from v$process; COUNT(1)---------- 24 |
1 2 3 4 5 | SQL> select count(1) from v$process; COUNT(1)---------- 23 |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | SQL> select sid, s.serial#, status from v$process p, v$session swhere paddr=addrand s.username='USR'; SID SERIAL# STATUS---------- ---------- -------- 9 10 SNIPEDSQL> alter system kill session '9,10' immediate;System altered.SQL> select s.status, count(1), s.username from v$process p, v$session swhere paddr(+)=addrgroup by s.status, s.usernameorder by 1;STATUS COUNT(1) USERNAME-------- ---------- ------------------------------ACTIVE 1 SYSACTIVE 16INACTIVE 2 SYSKILLED 1 USR 3 |
1 2 3 4 5 6 7 8 | SQL> /STATUS COUNT(1) USERNAME-------- ---------- ------------------------------ACTIVE 1 SYSACTIVE 16INACTIVE 2 SYS 3 |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | SQL> select spid, status from v$process p, v$session swhere paddr=addrand s.username='USR';SPID STATUS------------ --------2795 SNIPED[oracle@localhost ~]$ kill -9 2795SQL> select spid, status from v$process p, v$session swhere paddr=addrand s.username='USR';no rows selectedSQL> |
1 2 3 4 5 6 7 | SQL> select sysdate from dual;select sysdate from dual*ERROR at line 1:ORA-03135: connection lost contactSQL> |
Open Database in Restricted Mode
Restricted mode will only allow users with RESTRICTED SESSION privileges to access the database (typically DBA’s).
We use the startup restrict command to open the database in restricted mode as seen in this example.
-- Put the database in restricted mode.
Any users connected to the Oracle instance when going into restricted mode will remain connected; they must be manually disconnected from the database by exiting gracefully or by the DBA with the “alter system kill session” command.
We use the startup restrict command to open the database in restricted mode as seen in this example.
SQL> startup restrict;
-- Put the database in restricted mode.
SQL> alter system enable restricted session;
SQL> alter system disable restricted session;
SQL> select logins from v$instance;
ALLOWED | RESTRICTEDAny users connected to the Oracle instance when going into restricted mode will remain connected; they must be manually disconnected from the database by exiting gracefully or by the DBA with the “alter system kill session” command.
SQL> alter system kill session 'session-id, session-serial';
Monday, 9 April 2012
What is LOGGING,NOLOGGING and FORCE LOGGING
Nologging
NOLOGGING can be used to minimize the amount of redo generated by Oracle. NOLOGGING affect the recoverability.
Only the following operations can make use of nologging:
1.SQL*Loader in direct mode the +append hint
1.SQL*Loader in direct mode the +append hint
Additionally, a direct load with SQL*Loader and a direct load insert can also make use of nologging. The direct load insert is a special form of the insert statement that uses the /*+ append */ hint.
Note: Even though direct path load reduces the generation of redo, it is not totally eliminated. That's because those inserts still generate undo which in turn generates redo.
Note: Even though direct path load reduces the generation of redo, it is not totally eliminated. That's because those inserts still generate undo which in turn generates redo.
That means that ordinary inserts, updates and deletes always generate redo, no matter if the underlying table or index is specifed with nologging or not.
If there is an index on the table, and an +append insert is made on the table, the indexes will produce redo. This can be circumvented by setting the index to unusable and altering the session's skip_unusable_indexes to true.
Nologging can be overriden at tablespace level using alter tablespace ... force logging.
Nologging has no effect if the database is in force logging mode (which can be controlled with
alter database force [no] logging mode). 2.CTAS (create table as select)
3.ALTER TABLE statements (move/add/split/merge/modify partitions)
- alter table ... move partition
- alter table ... split partition
- alter table ... add partition (if hash partition)
- alter table ... merge partition
- alter table ... modify partition
- add subpartition
- coalesce subpartition
- rebuild unusable indexes
- alter index ... rebuild
- alter index ... rebuild partition
- create index
4.ALTER INDEX statements (move/add/split/merge partitions)
5.Check any datafile or tablespace contains BEGIN backup mode
6.INSERT, UPDATE, and DELETE on LOBs in NOCACHE NOLOGGING mode stored out of line
To create a table in NOLOGGING mode:
SQL> CREATE TABLE t1 (c1 NUMBER) NOLOGGING;
5.Check any datafile or tablespace contains BEGIN backup mode
6.INSERT, UPDATE, and DELETE on LOBs in NOCACHE NOLOGGING mode stored out of line
To create a table in NOLOGGING mode:
SQL> CREATE TABLE t1 (c1 NUMBER) NOLOGGING;
Table created.
To enable NOLOGGING for a table:
ALTER TABLE t1 NOLOGGING;
To enable NOLOGGING for a table:
ALTER TABLE t1 NOLOGGING;
Table altered.
Force logging
Force logging
FORCE LOGGING can be used on tablespace or database level to force logging of changes to the redo. This may be required for sites that are mining log data, using Oracle Streams or using Data Guard (standby databases). oracle introduced the ALTER DATABASE FORCE LOGGING command in Oracle 9i R2.
A tablespace or the entire database is either in force logging or no force logging mode. To see which it is, run:
SQL> SELECT force_logging FROM v$database;
A tablespace or the entire database is either in force logging or no force logging mode. To see which it is, run:
SQL> SELECT force_logging FROM v$database;
FOR ---
NO
or
SQL> SELECT tablespace_name, force_logging FROM dba_tablespaces;
or
SQL> SELECT tablespace_name, force_logging FROM dba_tablespaces;
TABLESPACE_NAME FOR ------------------------------ ---
SYSTEM NO ...
To enable force logging:
SQL> ALTER DATABASE force logging;
To enable force logging:
SQL> ALTER DATABASE force logging;
Database altered.
SQL> ALTER TABLESPACE users FORCE LOGGING;
SQL> ALTER TABLESPACE users FORCE LOGGING;
Tablespace altered.
To disable:
SQL> ALTER DATABASE no force logging;
To disable:
SQL> ALTER DATABASE no force logging;
Database altered.
SQL> ALTER TABLESPACE users NO FORCE LOGGING;
SQL> ALTER TABLESPACE users NO FORCE LOGGING;
Tablespace altered.
Sunday, 8 April 2012
Script to find export dumpfile version
The below script presented by one of Oracle expert in forums will help us to know dumpfile details like version etc. It also helps us in identifying if it is a classic export dumpfile or datapump dumpfile
set verify off
set define on
accept a_filename char prompt ‘Filename: ‘
accept a_directory char prompt ‘Directory: ‘
declare
fn varchar2(256) := ‘&&a_filename’;
dir varchar2(30) := ‘&&a_directory’;
info ku$_dumpfile_info;
ft number;
h number;
js dba_datapump_jobs.state%type;
begin
sys.dbms_datapump.get_dumpfile_info(
fn,
dir,
info,
ft
);
if ft = 0 then
dbms_output.put_line(‘File not recognized.’);
elsif ft = 1 then
–dbms_output.put_line(‘File is DataPump export file.’);
/* can we attach it to a DP job? */
begin
h := dbms_datapump.open (
‘SQL_FILE’,
‘FULL’
);
dbms_datapump.add_file (h,
‘examine_’||fn||’.log’,
dir,
null, — job name
sys.dbms_datapump.ku$_file_type_log_file
);
dbms_datapump.add_file (h,
fn,
dir,
null, — job name
sys.dbms_datapump.ku$_file_type_dump_file
);
dbms_datapump.stop_job(h);
dbms_output.put_line(‘File is DataPump export file.’);
exception
when dbms_datapump.INVALID_ARGVAL then
dbms_output.put_line(‘File is ORACLE_DATAPUMP External table file.’);
dbms_datapump.stop_job(h);
when others then
dbms_output.put_line(sqlerrm);
dbms_datapump.stop_job(h);
end;
elsif ft = 2 then
dbms_output.put_line(‘File is Classic export file.’);
else
dbms_output.put_line(‘Undocumented, file type is: ‘||to_char(ft));
end if;
/* appears that external tables are recognized as DataPump files but cannot be imported:
ORA-39000: bad dump file specification
ORA-31619: invalid dump file “C:\temp\DW_INSTR_CMPNT.DP”
*/
end;
/
Different ways to get dumpfile version & other information
Lets suppose we have a dumpfile and we have no clue from which database or atleast which version of database it is exported. (assume we don’t have a log file)
We got a request to import it to other database. As per the compatibility matrix you can import only to higher versions and for this we need to know current dumpfile version.
In this situation, the following methods will help you….
Method # 1
__________
__________
For classic export dump files on Unix systems, you can use below command
$ cat /tmp/scott_export.dmp | head | strings
Note that scott_export.dmp is the dumpfile name in my example
Method # 2
__________
Method # 2
__________
You can generate a trace file which extracts so much of information
$ impdp DIRECTORY=dp_dir DUMPFILE=scott_export.dmp NOLOGFILE=y SQLFILE=impdp_s.sql TABLES=notexist TRACE=100300
A sample output is as follows
KUPF: In kupfioReadHeader…
KUPF: 16:31:56.121: newImpFile: EXAMINE_DUMP_FILE
KUPF: 16:31:56.121: ……DB Version = 10.02.00.03.00
KUPF: 16:31:56.121: File Version Str = 1.1
KUPF: 16:31:56.121: File Version Num = 257
KUPF: 16:31:56.131: Version CapBits1 = 32775
KUPF: 16:31:56.131: ……Has Master = 0
KUPF: 16:31:56.131: ……..Job Guid = B94302C5DAB344E1876105E3295269C6
KUPF: 16:31:56.131: Master Table Pos = 0
KUPF: 16:31:56.131: Master Table Len = 0
KUPF: 16:31:56.131: …..File Number = 1
KUPF: 16:31:56.131: ……Charset ID = 46
KUPF: 16:31:56.131: …Creation date = Thu Jul 13 15:25:32 2011
KUPF: 16:31:56.141: ………..Flags = 2
KUPF: 16:31:56.141: ……Media Type = 0
KUPF: 16:31:56.141: ……..Job Name = “SYSTEM”.”SYS_EXPORT_FULL_01″
KUPF: 16:31:56.141: ……..Platform = IBMPC/WIN_NT-8.1.0
KUPF: 16:31:56.141: ……..Language = WE8ISO8859P15
KUPF: 16:31:56.141: …….Blocksize = 4096
KUPF: 16:31:56.141: newImpFile: file; /tmp/scott_export.dmp, FID; 1
KUPF: 16:31:56.151: In expandwildcard. wildcard count = 1
KUPF: In kupfxExmDmpFile…
KUPF: In kupfuExmDmpFile…
KUPF: In kupfioReadHeader…
Note : The above method I tried on a 10g version database. Plz check on a test 9i database before yourun on prod
Method # 3
__________
KUPF: 16:31:56.121: newImpFile: EXAMINE_DUMP_FILE
KUPF: 16:31:56.121: ……DB Version = 10.02.00.03.00
KUPF: 16:31:56.121: File Version Str = 1.1
KUPF: 16:31:56.121: File Version Num = 257
KUPF: 16:31:56.131: Version CapBits1 = 32775
KUPF: 16:31:56.131: ……Has Master = 0
KUPF: 16:31:56.131: ……..Job Guid = B94302C5DAB344E1876105E3295269C6
KUPF: 16:31:56.131: Master Table Pos = 0
KUPF: 16:31:56.131: Master Table Len = 0
KUPF: 16:31:56.131: …..File Number = 1
KUPF: 16:31:56.131: ……Charset ID = 46
KUPF: 16:31:56.131: …Creation date = Thu Jul 13 15:25:32 2011
KUPF: 16:31:56.141: ………..Flags = 2
KUPF: 16:31:56.141: ……Media Type = 0
KUPF: 16:31:56.141: ……..Job Name = “SYSTEM”.”SYS_EXPORT_FULL_01″
KUPF: 16:31:56.141: ……..Platform = IBMPC/WIN_NT-8.1.0
KUPF: 16:31:56.141: ……..Language = WE8ISO8859P15
KUPF: 16:31:56.141: …….Blocksize = 4096
KUPF: 16:31:56.141: newImpFile: file; /tmp/scott_export.dmp, FID; 1
KUPF: 16:31:56.151: In expandwildcard. wildcard count = 1
KUPF: In kupfxExmDmpFile…
KUPF: In kupfuExmDmpFile…
KUPF: In kupfioReadHeader…
Note : The above method I tried on a 10g version database. Plz check on a test 9i database before yourun on prod
Method # 3
__________
From Oracle 10g, you have another way to do this. We can use DBMS_DATAPUMP.GET_DUMPFILE_INFO package to read the dumpfile header where this information will be stored. For this we need to use pre-defined stored procedure.
To get the procedure script and other details, refer to MOS doc 462488.1
Note : You can also use this procedure on a 9i database, but it will not give complete details (but you will get version)
Method # 4
__________
__________
You can use a script which is mentioned in my previous post. For the script CLICK HERE
How to use PARALLEL parameter in Datapump?
Many a times, we may observe that datapump is running slow even after using PARALLEL option. But, we don’t know that there is a method to calculate value for PARALLEL parameter. Below information will helps us to do that…
DATAPUMP will use two methods to export/import data
a. DIRECT PATH
2. EXTERNAL TABLES
a. DIRECT PATH
2. EXTERNAL TABLES
It is upto datapump to decide which path it can work. Means, it may happen that some tables are exported/imported through direct path and some other using external tables in the same datapump job.
1. Value for PARALLEL parameter in datapump can be set to more than one only in Enterprise Edition.
1. Value for PARALLEL parameter in datapump can be set to more than one only in Enterprise Edition.
2. PARALLEL will not work effectively on Jobs with more metadata
3. As we know, in datapump, a master process will control entire process of export/import through worker processes. These worker process will start parallel execution (PX) processes to do that actual work. We can increase or decrease parallelism at any moment using interactive prompt.
4. If the worker processes are active, then even though we decrease the value for parallel, it will not be affective till the work reaches a completion point. But, increase in parallel processes will take affect immediately.
5. For Data Pump Export, the value that is specified for the parallel parameter should be less than or equal to the number of files in the dump file set (if you specified dump files exclusively and not used %U option)
HOW EXPORT WITH PARALLEL WORKS
HOW EXPORT WITH PARALLEL WORKS
1. Master process will start multiple worker processes. Atleast 2 worker processes will be created in case of export, one is for metadata and other is for table data.
2. You might have observed that datapump export will give estimated data size (even if we don’t mention ESTIMATE option). This is to calculate the number of parallel execution (PX) processes.
3. The columns of the tables are observed next, to decide whether to go for direct path or external tables method
Note: Direct path doesn’t support PARALLEL more than one
4. If the external tables method is chosen, Data Pump will determine the maximum number of PX processes that can work on a table data. It does this by dividing the estimated size of the table data by 250 MB and rounding the result down. If the result is zero or one, then PX processes are not used
Example : If the data size is 1000MB, it will be divided by 250MB which results in 4 i.e one process is for metadata and 1 process for data. again the worker process of data will have 4 corresponding PX processes. So, the total number of processes are 6.
Note : PX proceeses information will not be shown when we check through STATUS command
So, in the above example, we will see only 2 processes instead of 6 if we use STATUS command
5. Even though we give more PARALLEL value, Oracle will calculate worker and PX processes as above only.
Example : if we give PARALLEL=10 in above example, still Oracle uses 6 only
Note : We need to remember that Oracle will not scale up the processes if we mention less value to PARALLEL. So, we need to give more value any time in order to get maximum benefit
HOW IMPORT WITH PARALLEL WORKS
The PARALLEL parameter works a bit differently in Import because there are various dependencies and everything must be done in order.
Data Pump Import processes the database objects in the following order:
1. The first worker begins to load all the metadata: the tablespaces, schemas, etc., until all the tables are created.
2. Once the tables are created, the first worker starts loading data and the rest of the workers start loading data
3. Once the table data is loaded, the first worker returns to loading metadata again i.e for Indexes or other objects. The rest of the workers are idle until the first worker loads all the metadata
Note: One worker creates all the indexes but uses PX processes up to the PARALLEL value so indexes get created faster.
Thus, an import job can be started with a PARALLEL = 10, and the user will only see one worker being utilized at certain points during job execution. No other workers or Parallel Execution Processes will be working until all the tables are created. When the tables are created, a burst of workers and possibly PX processes will execute in parallel until the data is loaded, then the worker processes will become idle.
Before starting any export/import, it is better to use ESTIMATE_ONLY parameter. Divide the output by 250MB and based on the result decide on PARALLEL value
Finally when using PARALLEL option, do keep below points in mind
Before starting any export/import, it is better to use ESTIMATE_ONLY parameter. Divide the output by 250MB and based on the result decide on PARALLEL value
Finally when using PARALLEL option, do keep below points in mind
a. Set the degree of parallelism to two times the number of CPUs, then tune from there.
b. For Data Pump Export, the PARALLEL parameter value should be less than or equal to the number of dump files.
c. For Data Pump Import, the PARALLEL parameter value should not be much larger than the number of files in the dump file set.
For more details, you can refer to MOS doc 365459.1
b. For Data Pump Export, the PARALLEL parameter value should be less than or equal to the number of dump files.
c. For Data Pump Import, the PARALLEL parameter value should not be much larger than the number of files in the dump file set.
For more details, you can refer to MOS doc 365459.1
Subscribe to:
Posts (Atom)